LMS自适应滤波器是使滤波器的输出信号与期望响应之间的误差的均方值为最小,因此称为最小均方(LMS)自适应滤波器。其原理及推导见http://download.csdn.net/source/432206。
1 |
|
运行后的结果如下:
LMS自适应滤波器是使滤波器的输出信号与期望响应之间的误差的均方值为最小,因此称为最小均方(LMS)自适应滤波器。其原理及推导见http://download.csdn.net/source/432206。
1 |
|
运行后的结果如下:
帮同学编个LMS(Least Mean Squre)自适应滤波器算法,有许多基本概念都不知道,所以就上网搜了搜,长长见识。
滤波器是一种用来消除干扰杂讯的器件,将输入或输出经过过滤而得到纯净的交流电。您可以通过基本的滤波器积木块——二阶通用滤波器传递函数,推导出最通用的滤波器类型:低通、带通、高通、陷波和椭圆型滤波器。
传递函数的参数——f0、d、hHP、hBP 和hLP,可用来构造所有类型的滤波器。转降频率f0为s项开始占支配作用时的频率。设计者将低于此值的频率看作是低频,而将高于此值的频率看作是高频,并将在此值附近的频率看作是带内频率。阻尼d用于测量滤波器如何从低频率转变至高频率,它是滤波器趋向振荡的一个指标。实际阻尼值从0至2变化(表1)。高通系数hHP是对那些高于转降频率的频率起支配作用的分子的系数。带通系数hBP是对那些在转降频率附近的频率起支配作用的分子的系数。低通系数hLP是对那些低于转降频率的频率起支配作用的分子的系数。设计者只需这5个参数即可定义一个滤波器。
凡是有能力进行信号处理的装置都可以称为滤波器。在近代电信装备和各类控制系统中,滤波器应用极为广泛;在所有的电子部件中,使用最多,技术最复杂要算滤波器了。滤波器的优劣直接决定产品的优劣,所以,对滤波器的研究和生产历来为各国所重视。
1917年美国和德国科学家分别发明了LC滤波器,次年导致了美国第一个多路复用系统的出现。50年代无源滤波器日趋成熟。自60年代起由于计算机技术、集成工艺和材料工业的发展,滤波器发展上了一个新台阶,并且朝着低功耗、高精度、小体积、多功能、稳定可靠和价廉方向努力,其中小体积、多功能、高精度、稳定可靠成为70年代以后的主攻方向,导致RC有源滤波器 、数字滤波器、开关电容滤波器和电荷转移器等各种滤波器的飞速发展。到70年代后期,上述几种滤波器的单片集成被研制出来并得到应用。80年代致力于各类新型滤波器性能提高的研究并逐渐扩大应用范围。90年代至今在主要致力于把各类滤波器应用于各类产品的开发和研制。当然,对滤波器本身的研究仍在不断进行。
我国广泛使用滤波器是50年代后的事,当时主要用于话路滤波和报路滤波。经过半个世纪的发展,我国滤波器在研制、生产应用等方面已有一定进步,但由于缺少专门研制机构,集成工艺和材料工业跟不上来,使许多新型滤波器的研制应用与国际水平有一段距离。
滤波器可分为模拟滤波器和离散滤波器两大类。其中模拟滤波器又可分为有源、无源、异类三个分类;离散滤波器又可分为数字、取样模拟、混合三个分类。当然,每个分类又可继续分下去,总之,它们的分类可以形成一个树形结构。
按选择物理量分类
滤波器可分为频率选择、幅度选择、时间选择(例如PCM制中的话路信号)和信息选择(例如匹配滤波器)等四类滤波器。
按频率通带范围分类
滤波器可分为低通、高通、带通、带阻、全通五个类别,而梳形滤波器属于带通和带阻滤波器,因为它有周期性的通带和阻带。
滤波器种类繁多,下面着重介绍近年来发展很快的几种滤波器。
有源滤波器
有源滤波器由下列一些有源元件组成:运算放大器、负电阻、负电容、负电感、频率变阻器(FDNR)、广义阻抗变换器(GIC)、负阻抗变换器(NIC)、正阻抗变换器(PIC)、负阻抗倒置器(NII)、正阻抗倒置器(PII)、四种受控源,另外,还有病态元件极子和零子。
1965年单片集成运算放大器问世后,为有源滤波器开辟了广阔的前景,到70年代初期,有源滤波器发展最为注目,1978年单片RC有源滤波器问世,为滤波器集成迈进了可喜的一步。由于运放的增益和相移均为频率的函数,这就限制了RC有源滤波器的频率范围,一般工作频率为20KHz左右,经过补偿后,工作频率也限制在100KHz以内。1974年产生了有源滤波器,使工作频率可达GB/4(GB为运放增益与带宽之积)。由于R(电阻)的存在,给集成工艺造成困难,于是又出现了有源C(电容)滤波器:就是说,滤波器由C和运放组成。这样容易集成,更重要是提高了滤波器的精度,因为有源C滤波器的性能只取决于电容之比,与电容绝对值无关。但它有一个主要问题:由于各支路元件均为电容,所以运放没有直流反馈通道,使稳定性成为难题。1982年由Geiger、Allen和Ngo提出用连续的开关电阻(SR)去替代有源RC滤波器中的电阻R,就构成了SRC滤波器,它仍属于模拟滤波器。但由于采用预置电路和复杂的相位时钟,这种滤波器发展前途不大。
总之,以RC有源滤波器为原型的各类变种有源滤波器去掉了电感器,体积小,Q值可达1000,克服了RLC无源滤波器体积大、Q值小的缺点。但它仍有许多课题有待进一步研究:理想运放与实际特性的偏差;由于有源滤波器混合集成工艺的不断改进,单片集成有待进一步研究;应用线性变换方法探索最少有源元件的滤波器需要继续探索;元件的绝对值容差的存在,影响滤波器精度和性能等问题仍未解决;由于R存在,占芯片面积大、电阻误差大(20~30%)、线性度差等缺点,大规模集成仍然有困难。
开关电容滤波器(SCF)
80年代技术改造一个重大课题是实现各种电子系统全面大规模集成(LSI),使用最多的滤波器成为”拦路虎”,RC有源滤波器不能实现LSI,无源滤波器和机械滤波器更不用说。人们只能另辟新径。50年代有人提出SCF的概念,由于当时集成工艺不过关,并没有引起人们的重视,直到72年,美国一个叫Fried的科学家用开关和电容模拟电阻R,说SCF的性能只取决于电容之比,与电容绝对值无关,这样才引起人们的重视。1979年一些发达国家单片SCF已成为商品(属于高度保密技术),现在SC技术已趋成熟。SCF并用MOS工艺加以实现公认为80年代网络理论与集成工艺的一大突破。当前MOS电容值一般为几PF~100PF之内,它具有(10~100) 10-6/V的电压系数与(10~100) 10-6/℃的温度系数,这两个系数几乎接近理想的境界。SCF具有下列一些优点:可以大规模集成;精度高;功能多,几乎所有电子部件和功能均可以由SC技术来实现;比数字滤波器简单,因为不需要A/D,D/A转换;功能小,可以做到。
SCF的应用情况:以声频范围应用为主体,工作频率在100KHz之内;在信号处理方面的应用有:程控SCF、模拟信号处理、振动分析、自适应性滤波器、音乐综合、共振谱、语言综合器、音调选择、语声编码、声频分析、均衡器、解调器、锁相电路、离散傅氏变换……。总之,SCF在仪表测量、医疗仪器、数据或信息处理等许多领域都有广泛的应用前景。
在我国,1978年,有的导师和在校研究生开始进行这项研究工作,真正引起人们重视是80年以后。83年清华大学已制成单片SCF,成都工程学院与工厂联合,也研制成单片SCF。现在关键是MOS工艺实现SCF及推广应用问题,由于用户还不了解它,SCF的应用还没有普及。
SCF还有许多课题有待研究:1、由于运放和控制MOS开关的采样频率所限制,SCF只能在音频范围内应用。近年虽然出现无运放的SC电路,但由于采样频率的限制,工作频率最高只在1MHZ之内。2、非零的MOS开关的沟道电阻以及非理想的运放特性,均可使SCF造成误差。3、开关电容本身的寄生电容将使SCF的频响发生畸变。4、MOS开关与MOS运放的热噪声将使SCF的动态范围受到限制。5、最终要以MOS工艺来实现的SCF,由于它是时变网络,想用分立元件精确模拟是不可能的,因此,设计完善的CAD技术是解决这一问题的唯一手段。此外,在灵敏度分析、噪声分析等方面均有许多课题有待研究。
大家对DF并不陌生,这里不作系统综述,但对一些新型DF做一些介绍:
1.自适应DF
最优控制、自适应控制和自学习控制都涉及到多参数、多变量的复杂控制系统,都属于现代控制理论研究的课题。自适应DF具有很强的自学习、自跟踪功能。它在雷达和声纳的波束形成、缓变噪声干扰的抑制、噪声信号的处理、通信信道的自适应均衡、远距离电话的回声抵消等领域获得了广泛的应用,促进了现代控制理论的发展。
自适应DF有如下一些简单算法:W-LMS算法;M-LMS算法;TDO算法;差值LMS算法和C-LMS算法。
2.复数DF
在输入信号为窄带信号处理系统中,常采用复数DF技术。为了降低采样率而保存信号所包含的全部信息,可利用正交双路检波法,取出窄带信号的复包络,然后通过A/D变换,将复包络转化为复数序列进行处理,这个信号处理系统即为复数DF。它具有许多功能。MTI雷达中抑制具有卜勒频移的杂波干扰;数字通信网与模拟通信网之间多路TDM/FDM信号变换复接等等。
3.多维DF
在图象处理、地震、石油勘探的数据处理中都用到多维DF(常用是二维DF),多维DF的设计,往往将一维DF优化设计直接推广到多维DF中去。对于模糊和随机噪声干扰的二维图象的处理,多维DF也能发挥很好的作用。
此外,还有波DF,它便于实现大规模集成;便于无源和有源滤波网络的数字模拟。
对于DF有待研究的课题有:系数灵敏度;舍入噪声和极限环;多维逆归滤波器的稳定性;各种硬件和软件实现DF的研究等等。
介绍几种已得到广泛应用的新型滤波器:
1.电控编程CCD横向滤波器(FPCCDTF)
电荷耦合器(CCD)固定加权的横向滤波器(TF)在信号处理中,其性能和造价均可与数字滤波器和各种信号处理部件媲美。这种滤波器主要用于自适应滤波;P-N序列和Chirp波形的匹配滤波;通用化的频域滤波器以及作相关、褶积运算;语音信号和相位均衡;相阵系统的波束合成和电视信号的重影消除等。
2.晶体滤波器
它是适应单边带技术而发展起来的。在70年代,集成晶体滤波器的产生,使它发展产生一个飞跃,近十年来,对晶体滤波器致力于下面一些研究:实现最佳设计,除具有优良的选择外,还具有良好的时域响应;寻求新型材料;扩展工作频率;改造工艺,使其向集成化发展。它广泛应用于多路复用系统中作为载波滤波器,在收发信中、单边带通信机中作为选频滤波器,在频谱分析仪和声纳装置中作为中频滤波器。
3.声表面波滤波器
它是理想的超高频器件。它的幅频特性和相位特性可以分别控制,以达到要求,体积小,长时间稳定性好和工艺简单。通常应用于:电视广播发射机中作为残留边带滤波器;彩色电视接收机中调谐系统的表面梳形滤波器,此外,在国防卫星通信系统中已广泛采用。声表面波滤波器是电子学和声学相结合的产物,而且可以集成。所以,它在所有无源滤波器中最有发展前途。
说明:原文见于http://www.psp-programming.com/tutorials/c/lesson01.htm
初次翻译,错误难免,还请见谅。
我们有一系列关于如何自制PSP(Playstation Potable)软件的教程,这份将是第一期。如果你正在读这个,恭喜你,作为程序员你遇到了一个大障碍。和刚开始编程时遇到的麻烦一样。好了,开始阅读教程了。
要创建你自己的程序,第一步就是要建立开发环境。该开发环境能可以将源代码编译成可以在PSP上执行的文件。我们将要在操作系统上安装两个重要的工具软件。
第一个工具叫做CYGWIN,这是一个用于Windows平台上的Linux模拟器,它可以在你的电脑上创建一个模拟的Linux环境,只有这样才可以运行一些必须在Linux下运行的程序。听起来有点可怕,不过不用担心,其实很容易用的。
需要的第二个东西就时toolchain。这是PSP编程的关键,提供了你所需要的一切,包括头文件、库、编译器和一些例程。安装了这个之后,你就可以开始编写自己的第一个程序了。
现在开始介绍颇不急待想要了解的部分:开发环境的安装。
第一步就是安装CYGWIN。先在CYGWIN网站上下载CYGWIN的安装程序。
下载好之后,打开该可执行文件,会闪现一个安装界面;点击“next”按钮,此时你将可以看到有三个选项,选择默认选项“Install from Internet”,点击“next”;确定在那个目录下安装CYGWIN,如过不想将其安装在“C:/cygwin”处则更改之即可(C:是本地磁盘),其他选项设为默认,点击next;现在又提示让你确定“在哪里存放下载的安装文件”,这个选项无关紧要,不过最好将其放在一个自己可以找到的目录下,以便安装完之后删除。选定了合适的地方之后,点击next;下一屏会问你你的网络设置,如果你没有使用代理(或者不知道代理是甚么),直接点next。如果不行的话,返回上一步让他用IE浏览器的设置;然后,会提供一个下载安装文件的服务器列表,任何一个都可以,选择一个点击next;现在开始下载安装文件包列表,得几分钟时间,依赖于你的网速;下载完之后,拖动滑块,在“devel”哪里点击“default”使得它变成“install”。继续拖动滑块,将“Web”下面的“wget”设置为“install”。完成之后,点击next。CYGWIN将会被下载然后安装选择了的包。这个可能会用掉很长时间,所以等待的时候你可以看看电视或者浏览其他网页。完成CYGWIN安装之后,准备安装toolchain。
现在我们就可以在CYGWIN环境下安装toolchain了。为了建立开放环境,首先必须运行CYGWIN。从开始菜单或者“C:/cygwin”目录下,运行一个CYGWIN bash shell(cygwinbat)。会打开一个命令行,当可以看到“yourusername@yourcomputername~”,说明你的CYGWIN环境已经成功建立了,此时就可以关闭该窗口。
下载最新的toolchain(点击此处),在最上面就可以看见了,下载该文件。下载完成之后,使用winrar将其解压缩至“C:/cygwin/home/user”文件目录下,这里的“user”是你的用户名。现在就可以安装toolchain了。再次打开CYGWIN bash shell,现在是时候介绍一些Linux命令行了,在一行的开头有“$”这个符号,它意味着正在运行的shell是在用户模式下,和根(管理员)模式相对。这一点在CYGWIN中是很重要的,如果你不曾使用过Linux命令行的话,这一点也是要注意的。
现在需要改变目录至刚解压缩的toolchain目录下,在bash shell 中打“ls”,它代表list,会给出当前目录下所有文件的名称和其他信息(和Windows下的dir命令相似。现在就应该可以看见一个“psptoolchain”的文件夹,这就是我们所想要改变的目录。因此打“cd psptoolchain”然后按回车。CD代表改变文件目录(Change Directory),该命令会改变当前操作的目录。此刻打“ls”命令,就可以看见所有包含在“psptoolchain”目录下的文件。这里有一个我们将要用于创建所有东西的文件“toolchain.sh”。
由于toolchain的最近问题,我们必须更新所有的东西。因此更新和修改toolchain脚本,必须使用“svn update”然后回车。
结束之后输入“./toolchain.sh”执行更新后的脚步然后回车。在Linux下,“.”表示当前目录,而“..”表示父层目录。所以该命令表示执行在当前目录下的“toolchain.sh”脚本。Toolchain.sh脚步将会为你完成剩下的所有工作。这个会花掉近几个小时,依赖于你得机器配置。
漫长得等待终于结束了,现在可以进行最后一步了。必须告知CYGWIN在哪里可以找到PSPSDK(toolchain安装的)和toochian。为了实现上述目标,必须改变“C:/cygwin/cygwin.bat ”文件使它包含一些路径。关闭CYGWIN,然后使用资源管理器在“C:/cygwin”目录下右键点击“cygwin.bat”。选择“编辑”后弹出一个记事本窗口,显示的内容如下:
1 | @echo off |
将其改为:
1 | @echo off |
现在PSP游戏开放环境就建立好了。如果你现在有源代码的话就可以编译了,使用cd命令进入到源代码目录下,用make命令进行编译,就会生成一个eboot.pbp文件,该文件就可以直接放入你的PSP中运行。如果没有的话,可以通过下一节的学习来创建你自己的简单应用程序。
面向对象是基于一种哲学思想,它认为:客观实体和实体之间的联系构成了现实世界的所有问题,而每一个实体都可以抽象为对象。这种思想尽可能地按照人类认识世界的方法和思维方式来分析和解决问题,使人们分析、设计一个系统的方法尽可能接近认识一个系统的方法。面向对象的基本观点可以概括如。(1)客观世界由对象组成,任何客观实体都是对象,复杂对象可以由简单对象组成。(2)具有相同数据和操作的对象可归纳成类,对象只是类的一个实例。(3)类可以派生出子类,子类除了继承父类的全部特性外还可以有自己的特性。(4)对象之间的联系通过消息传递来维系。由于类的封装性,它具有某些对外界不可见的数据,这些数据只能通过消息请求调用可见方法来访问。简单的来说,面向对象=对象+类+继承+消息。
面向对象分析(OOA)是指利用面向对象的概念和方法为软件需求建造模型,以使用户需求逐步精确化、一致化、完全化的分析过程。分析的过程也是提取需求的过程,主要包括理解、表达和验证。由于现实世界中的问题通常较为复杂,分析过程中的交流又具有随意性和非形式化等特点,软件需求规格说明的正确性、完整性和有效性就需要进一步验证,以便及时加以修正。面向对象分析中建造的模型主要有对象模型、动态模型和功能模型。其关键是识别出问题域中的对象,在分析它们之间相互关系之后建立起问题域的简洁、精确和可理解的模型。对象模型通常由五个层次组成:类与对象层、属性层、服务层、结构层和主题层,此五个层次对应着在面向对象分析过程中建立对象模型的五项主要活动:发现对象、定义类、定义属性、定义服务、设别结构。面向对象的分析过程如图1所示。
图1 面向对象分析过程模型
分析是提取和整理用户需求,并建立问题域精确模型的过程。面向对象设计(OOD)则是把分析阶段得到的需求转变成符合成本和质量要求的、抽象的系统实现方案的过程。从面向对象分析(OOA)到面向对象设计(OOD)是一个逐渐扩充模型的过程,也可以说面向对象设计是用面向对象观点建立求解域模型的过程。面向对象分析主要是模拟问题域和系统任务,而面向对象设计是面向对象分析的扩充,主要增加各种组成部分。面向对象设计的模型又五层组成,在设计期间主要扩充四个组成部分:人机交互部分、问题域、任务管理和数据管理。人机交互部分包括有效的人机交互所必须的实际显示和输入。问题域部分放置面向对象分析结果并管理面向对象分析的某些类和对象、结构、属性和方法。任务管理部分包括任务定义、通信和协调、硬件分配及外部系统。数据管理部分包括对永久性数据的访问和管理。面向对象设计模型如图2所示。
图2 面向对象设计模型
为了方便、高效地进行面向对象分析和设计,UML(Unified Modeling Language)被创造出来。UML是一种功能强大的、面向对象分析的可视化系统分析的建模语言,它采用一整套成熟的建模技术,广泛地适用于各个应用领域。运用UML进行面向对象分析设计,通常都要经过下述三个步骤。(1)识别系统的用例和角色。首先要对项目进行需求调研,分析项目的业务流程图和数据流程图,以及项目中涉及的各级操作人员,识别出系统中的所有用例和角色;接着分析系统中各角色和用例见的联系,使用UML建模工具画出系统的用例图;最后,勾画系统的概念层次模型,借助UML建模工具描述概念层的类和活动图。(2)进行系统分析并抽象出类。系统分析的任务是找出系统的所有要求并加以描述,同时建立特定领域模型。从实际需求抽象出类,并描述各个类之间的关系。(3)设计系统,并设计系统中的类及其行为。设计阶段由结构设计和详细设计组成。结构设计是高层设计,其任务是定义包(子系统)、包间的依赖关系和主要的通信机制。包有利于描述系统的逻辑组成以及各个部分之间的依赖关系。详细设计主要用来细化包的内容,清晰描述所有的类,同时使用UML的动态模型描述在特定环境下这些类的实例的行为。
用例图(Use Case Diagram)是由软件需求分析到最终实现的第一步,它描述人们如何使用一个系统。用例视图显示谁是相关的用户、用户希望系统提供什么样的服务,以及用户需要为系统提供的服务,以便使系统的用户更容易理解这些元素的用途,也便于软件开发人员最终实现这些元素。用例图在各种开发活动中被广泛的应用,但是它最常用来描述系统及子系统。
当用例视图在外部用户出现以前出现时,它捕获到系统、子系统或类的行为。它将系统功能划分成对参与者(即系统的理想用户)有用的需求。而交互部分被称作用例。用例使用系统与一个或者多个参与者之间的一系列消息来描述系统中的交互。
用例图包含六个元素,分别是:参与者(Actor)、用例(Use Case)、关联关系(Association)、包含关系(Include)、扩展关系(Extend)以及泛化关系(Generalization)。
用例图可一个包含注释和约束,还可一个包含包,用于将模型中的元素组合成更大的模块。有时,可以将用例的实例引入到图中。用例图模型如下所示,参与者用人形图标来标识,用例用椭圆来表示,连线表示它们之间的关系。
参与者是系统外部的一个实体,它以某种方式参与用例的执行过程。参与者通过向系统输入或请求系统输入某些事件来触发系统的执行。参与着由参与用例时所担当的角色来表示。在UML中,参与者用名字写在下面的人形图标表示。
每个参与者可以参与一个或多个用例。它通过交换信息与用例发生交互(因此也与用例所在的系统或类发生了交互),而参与者的内部实现与用例是不相关的,可以用一组定义其状态的属性充分的描述参与者。
参与者有三大类:系统用户、与所建造的系统交互的其它系统和一些可以运行的进程。
第一类参与者是真实的人,即用户,是最常见的参与者,几乎存在于每个系统中。命名这类参与者时,应当按照业务而不是位置命名,因为一个人可能有很多业务。
第二类参与者是其它的系统。这类位于程序边界之外的系统也是参与者。
第三类参与者是一些可以运行的进程,如时间。当经过一定的时间触发系统中的某个事件时,时间就成了参与者。
在获取用例前首先要确定系统的参与者,开发人员可以通过回答以下的问题来寻找系统的参与者。
a. 谁将使用该系统的主要功能。
b. 谁将需要该系统的支持以完成其工作。
c. 谁将需要维护、管理该系统,以及保持该系统处于工作状态。
d. 系统需要处理哪些硬件设备。
e. 与该系统那个交互的是什么系统。
f. 谁或什么系统对本系统产生的结果感兴趣。
在对参与者建模的过程中,开发人员必须要牢记以下几点。
a. 参与者对于系统而言总是外部的,因此它们可以处于人的控制之外。
b. 参与者可以直接或间接的与系统交互,或使用系统提供的服务以完成某件事务。
c. 参与者表示人和事物与系统发生交户时所扮演的角色,而不是特定的人或者特定的事物。
d. 每个参与者需要一个具有业务一样的名字,在建模中不推荐使用类似“新参与者”的名字。
e. 每一个参与者要必须有简短的描述,从业务角度描述参与者是什么。
f. 一个人或事物在与系统发生交互时,可以同时或不同时扮演多个角色。
g. 和类一样,参与者可以具有表示参与者的属性和可以接受的事件,但使用的不频繁。
因为参与者是类,所以多个参与者之间可以具有与类相同的关系。在用例视图中,使用了泛化关系来描述多个参与者之间的公共行为。如果系统中存在几个参与者,它们既扮演自身的角色 ,同时也扮演更具一般化的角色,那么就用泛化关系来描述它们。这种情况往往发生在一般角色的行为在参与者超类中描述的场合。特殊化的参与者继承了该超类的行为,然后在某些方面扩展了此行为。参与者之间的泛化关系用一个三角箭头来表示,指向扮演一般角色的超类。这与UML中类之间的返还关系符号相同。
用例是外部可见的系统功能单元,这些系统功能由系统单元所提供,并通过一系列系统单元与一个或多个参与者之间交换的消息所表达。用例的用途是,在不揭示系统内部构造的前提下定义连贯的行为。
用例的定义包含它所必须的所有行为——执行用例的主线次序、标准行为的不同变形、一般行为下的所有异常情况及其预期反应。从用户的角度来看,上述情况很可能是异常情况;从系统的角度来看,它们是必须被描述和处理的附加情况。更确切地说,用例不是需求或功能的规格说明,但是也展示和体现其所描述的过程中的需求情况。在UML中,用例用一个椭圆表示。
在模型中,每个用例的执行都独立与其它用例,尽管在执行一个用例时由于用例之间共享对象的原因可能会在用例之间产生隐含的依赖关系。每个用例都表示一个纵向的功能块,这个功能块的执行会和其它用例的执行混合在一起。
用例的动态执行过程可以用UML的交互来说明,可用用状态图、时序图、协作图或非正式的文字描述来表示。用例功能的执行通过系统中类之间的协作来实现。一个类可以参与多个协作,因此也参与了多个用例。
在系统层,用例表示整个系统对外部用户可见的行为。一个用例就像外部用户可以使用的系统操作。但是,它不又与操作不同,用例可以在执行过程中持续接受参与者的输入消息。用例也可以被像子系统和独立类这样的系统小单元所应用。一个内部用例表示了系统的一部分对其它部分呈现出的行为。例如,某个类的用例表示了一个连贯的功能块,这个功能块是该类提供给系统内其它有特定作用的类的。一个类可以有多个用例。
用例图对整个系统建模过程非常重要,在绘制系统用例图前,还有许多工作要做。系统分析者必须分析系统的参与者和用例,他们分别描述了“谁来做”和“做什么”这两个问题。
识别用例最好的方法就是从分析系统的参与者开始,考虑每一个参与者是如何使用系统的。使用这种策略的过程中可能会发现新的参与者,这对完善整个系统的建模有很大的帮助。用例建模的过程是一个迭代和逐步精华的过程,系统分析者首先从用例的名称开始,然后添加用例的细节信息。这些信息由简短的描述组成,它们被精华成完整的规格说明。
在识别用例的过程中,通过回答以下几个问题,系统分析者可以获得帮助。
a. 特定参与者希望系统提供什么功能。
b. 系统是否存储和检索信息,如果是,由哪个参与者触发。
c. 当系统改变状态时,是否通知参与者。
d. 是否存在影响系统的外部事件。
e. 哪个参与者通知系统这些事件。
用例分析处于系统的需求分析阶段,这个阶段应该尽量避免考虑系统实现的细节问题。但是要实际建立系统,则需要更加具体的细节,这些细节写在事件流文件中。事件流的目的是为用例的逻辑流程建立文档,这个文档详细描述系统用户的工作和系统本身的工作。
虽说事件流很详细,但其仍然是独立于实现的方法的。换句话说,事件流描述的是一个系统“做什么”而不是“怎么做”。事件流通常包括:简要说明、前提条件、主事件流、其它事件流和事后事件流。
a. 简要说明。
每个用例应当有一个相关的说明,描述该用例的作用,说明应当简明扼要,但应包括执行用例的不同类型的用户和通过这个用例要达到的结果。
b. 前提条件。
用例的前提条件列出用例之间必须满足的条件。例如,前提条件是另一个用例已经执行或用户具有运行当前用例的权限。但并不是所有用例都有前提条件。
c. 主事件流和其它事件流。
用例的具体细节在主事件流和其它事件流中描述。事件流是从用户角度描述执行用例的具体步骤,关注系统“做什么”,而不是“怎么做”。主事件流和其它事件流包括:用例如何开始和结束、用例如何与参与者交互、用例的正常流程(主流程)、用例主事件流(其它事件流)的变体和错误流。
d. 事后条件。
事后条件是用例执行完毕后必须为真的条件。例如,可以在用例完成之后设置一个标识,这种信息就是事后条件。与前提条件一样,事后条件可以增加用例次序方面的信息,如果要求一个用例执行完后必须执行另一个用,那么就可以在事后条件中说明这一点。当然,并不是每个用例中都有事后条件。
用例除了与参与者发生关系外,还可以具有系统中的多个关系,这些关系包括包含关系、扩展关系和泛化关系。应用这些关系的目的是为了从系统中抽取出公共行为和其变体。
关联关系描述参与者与用例之间的关系,它是用于表示类的挂系的关联元类的实例。在UML中,关联关系用箭头来表示。
关联关系表示参与者与用例之间的通信。不同的参与者可以访问相同的用例,一般说来它们和该用例的交互是不一样的,如果一样的话,说明它们的角色可能是相同的。如果两中交互的目的也相同,说明它们的角色是相同的,就可以将它们合并。
虽然每个用例的实例都是独立的,但是一个用例可以用其它的更简单的用例来描述。这有点像通过继承父类并增加附加描述来定义一个类。一个用例可以简单地包含其它用例具有的行为,并把它所包含的用例行为作为自身行为的一部分,这被称作包含关系。在这种情况下,新用例不是初始用例的一个特殊例子,并且不能被初始用例所代替。爱UML中,包含关系表示为虚线箭头交<
包含关系把几个用例的公共步骤分离成一个单独的被包含用例。被包含用例称作提供者用例,包含用例称作客户用例,提供者用例提供功能给客户使用。用例间的包含关系允许包含提供者用例的行为到客户用例的事件中。
包含关系使一个用例的功能可以在另一个用例中使用,如下所述。
a. 如果两个以上用例有大量一致的功能,则可以将这个功能分解到另外一个用例中。其它用例可以和这两个用例建立包含关系。
b. 一个用例的功能太多时,可以用包含关系建模两个小用例。
要使用包含关系,就必须在客户用例中说明提供者用例行为别包含的详细位置。这一点同功能调用有点类似。事实上,它们在某种程度上具有相似的语义。
一个用例也可以被定义为基础用例的增量扩展,这被称作扩展关系,扩展关系是把新的行为插入到已有的用例中的方法。同一个基础用例的几个扩展用例可以在一起应用。基础用例的扩展增加了原有的语义,此时基础用例而不是扩展用例被作为例子使用。在UML中,扩展关系表示为虚线箭头加<
基础用例提供了一组扩展点,在这些新的扩展点中可以添加新的行为,而扩展用例提供了一组插入片片段,这些片段能够被插入到基础用例的扩展点上。基础用例不必知道扩展用例的任何细节,它仅为其提供扩展点。事实上,基础用例即使没有扩展用例也是完整的,这点与包含关系有所不同。一个用例可能有多个扩展点,每个扩展点可以出现多次。但是一般情况下,基础用例的执行不和涉及到扩展用例,只有特定的条件发生,扩展用例才被执行。扩展关系为处理异常或构建灵活的系统框架提供了一种有效的方法。
一个用例可以被特别列举为一个或多个用例,这被称为用例泛化。当父用例能够被使用时,任何子用例也可以被使用。在UML中用例泛化与其它泛化关系的表示法相同,用一个三角箭头从子用例指向父用例。
在用例泛化中,子用例表示父用例的特殊形式。子用例从父用例处继承行为和属性,还可以添加、覆盖或改变继承的行为。如果系统中一个或多个用例是某个一般用例的特殊化时,就需要使用用例的泛化关系。
对于一个系统,会有一些事物存在于其内部,而一些事物存在于其外部。存在于系统内部的事物的任务是完成系统外部事物所期望的系统行为,存在于系统外部并与其进行交互的事物构成了系统的语境,即系统存在的环境。在UML建模中,用例图对系统的语境进行建模,强调的是系统的外部参与者。对系统语境建模应当遵循以下的方法:
a. 用以下几组事物来识别系统外部的参与者:需要从系统中得到帮助以完成其任务的组;执行系统功能时所必须的组;与外部硬件或其它软件系统进行交互的组;为了管理和维护而执行某些辅助功能的组。
b. 将类似的参与者组织成泛化/特殊化的结构层次。
c. 在需要加深理解的地方,为每个参与者提供一个构造型。
d. 将参与者放入到用例图中,并说明参与者与用例之间的通信路径。
需求就是根据用户对产品功能的期望,提出产品外部功能的描述。需要分析所要做的工作是获取系统的需求,归纳系统所要实现的功能,使最终的软件产品最大限度的贴近用户的要求。对系统需求建模可以参考以下的方法。
a. 识别系统外部的参与者来建立系统的语境。
b. 考虑每一个参与者期望的行为或需要系统提供的行为。
c. 把公共的行为命名为用例
d. 分解公共行为,放入到新的用例中以供其它的用例使用:分解异常行为,放入新用例中以延伸为主要的控制流。简而言之,就是确定提供者用例和扩展用例。
e. 在用例视图中对用例、参与者和它们之间的关系进行建模。
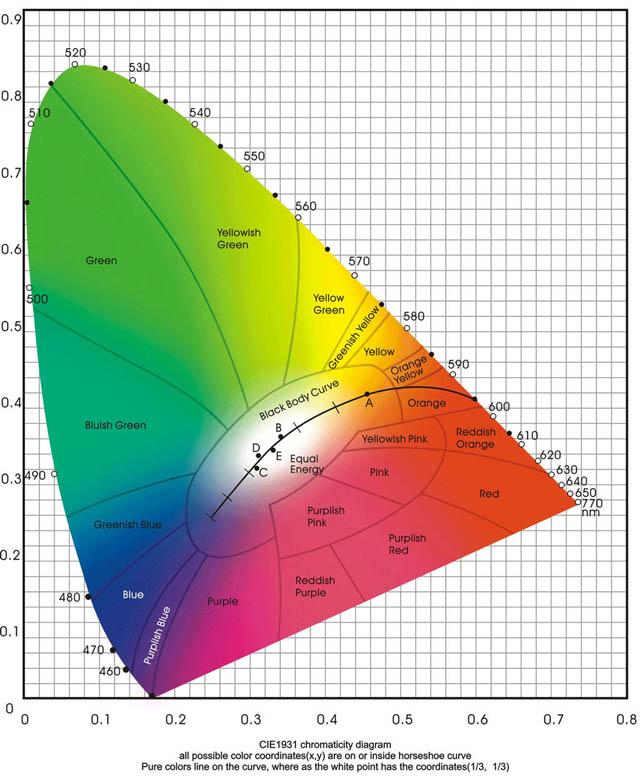
“色度图”在学术文献中的解释
Windows是消息驱动的,它的消息循环部分主要是通过GetMessage函数来处理消息的。操作系统为每一个创建的窗口维护着一个消息队列,当在该窗口上有事件发生时,操作系统就把该事件所对应的消息放入该窗口的消息队列中。应用程序要处理事件消息的话,就必须先将消息取出来,主要有两个函数可以实现:GetMessage和PeekMessage。
它们两者的功能有所不同:当消息队列中没有消息的时候GetMessage会挂起,将CPU资源让给其他应用程序,当有消息可以处理时,才获得CPU资源并处理。而PeekMessage则不管消息队列有无消息立即返回。
一般情况下,GetMessage可以在非FPS(Frame Per Second)应用程序中高效运行。但是当它在FPS(如:游戏)应用中运行时,有时回出现闪屏。故在FPS程序中最好还是用PeekMessage函数。
其用法如下:
1 | // 主消息循环: |
1 | // 主消息循环: |
动态链接库为模块化应用程序提供了一种方式,使得更新和重用程序更加方便。当几个应用程序在同一时间使用相同的函数时,它也帮助减少内存消耗,这是因为虽然每个应用程序有独立的数据拷贝,但是它们的代码却是共享的。
动态链接库是应用程序的一个模块,这个模块用于到处一些函数和数据供程序中的其他模块使用。应该从以下三个方面来理解:
动态链接库(Dynamic Link Library)的缩写为DLL,大部分动态链接库镜像文件的扩展名为dll,但扩展名为其他的文件也有可能是动态链接库,如系统中的某些exe文件,各种控件(ocx)等都是动态链接库
1 | BOOL APIENTRY DllMain( HANDLE hModule, |
hModule
参数是本DLL模块的句柄,即本动态链接库模块的实例句柄,数值上是这个文件的映像加载到进程的地址空间时使用的基地址。需要注意的是,在动态链接库中通过“GetModuleHandle(NULL)”语句得到的是主模块(可执行文件的映像)的基地址,而不是DLL文件的基地址。
ul_reason_for_call
参数表示本次调用的原因,可能是下4中情况的一种:
1. DLL_PROCESS_ATTACH 表示动态链接库刚被某个进程加载,程序可以在这里做一些初始化工作,并返回TRUE表示初始化成功,返回FALSE表示初始化出错,这样库的装载就会失败。这给动态链接库一个机会来阻止自己被装入。
2. DLL_PROCESS_DETACH 此时相反,表示动态链接库将被卸载,程序可以在这里进行一些资源的释放工作。
3. DLL_THREAD_ATTACH表示应用程序创建了一个线程。
4. DLL_THREAD_DETACH 表示某个线程正常终止了。
DLL能够定义两种函数,导出函数和内部函数。导出函数可以被其他模块调用,也可以被定这个模块调用,而内部函数只能被定义这个函数的模块调用。
动态链接库的主要功能是向外导出函数,供进程中其他模块使用。动态链接库中代码的编写也没什么特别之处,还要包含文件还可以使用资源,C++类等。
动态链接库工程编译后,在工程的Debug或者Release目录下会生成两个个有用的文件,.dll文件就是动态链接库,.lib文件是供程序开发用的导入库,.h文件包含了导出函数的声明。
调用DLL中的导出函数有两种方法:
第一种. 装载期间动态链接。
模块可以像调用本地函数一样调用从其他模块导出的函数(API函数就是这样用的)。装载期间链接必须使用DLL的导入库(.lib文件),它为系统提供了加载这个DLL和定位这个DLL中的导出函数所需的所有信息。
所谓装载期间链接,就是应用程序启动时由加载器(加载应用程序的组件)载入dll。载入器如何知道要载入哪些DLL呢?这些信息记录在可执行文件(PE文件)的idata节中。使用这种方法不用自己写代码显式的加载DLL。在程序只需:
1 | #include “ xxx.h” |
或者直接将xxx.lib文件添加到工程中,效果是一样的。
注意:
第二种. 运行期间动态链接是在程序运行过程中显示地去加载DLL库,从中导出所需的函数。
为了能够运行期动态的导出函数,一般需要在工程中建立一个DEF文件来指定要导出的函数。在新添的.def文件中写入如下内容:
EXPORTS
xxxFunction
这两行说明此DLL库要向外导出xxxFunction函数。
调用DLL导出函数时分两步进行。
1>. 加载目标DLL,如下代码:
HMODULE hModule=LoadLibrary(“xxx.dll”);
LoadLibrary函数的作用是加载指定目录下的DLL库到进程的虚拟地址空间,函数执行成功返回此DLL模块的句柄,否则返回NULL。事实上,载入器也是调用这个函数加载DLL的。在不使用DLL模块时,应该调用FreeLibrary函数释放它所占的资源。
2>. 取得目标DLL中导出函数的地址,这项工作由GetProcAddress函数来完成。
FARPROC GetProcAddress(
HMODULE hModule, // 函数所在模块的模块句柄
LPCSTR lpProcName // 函数的名称
)
函数执行成功返会函数的地址,失败返回NULL。
在使用方法一时,三个文件都会被用到,使用第二种方法时,只有.dll文件会被用到。
1 | // DllTest.cpp : Defines the entry point for the DLL application. |
1 | // DllTest.h |
1 | // DllTest.def |
1 | // DllUse1.cpp : Defines the entry point for the console application. |
1 | // DllUse2.cpp : Defines the entry point for the console application. |
Windows应用程序的运行模式是基于消息驱动的,任何线程只要注册了窗口类就会有一个消息队列来接收用户的输入消息和系统消息。为了取得特定线程接收或发送的消息,就要 Windows提供的钩子。
钩子(Hook)是Windows消息处理机制中的一个监视点,应用程序可以在这里安装一个子程序(钩子函数)以监视指定窗口某种类型的消息,所监视的窗口可以是其他进程创建的。当消息到达后,在目标窗口处理函数处理之前,钩子机制允许应用程序截获它进行处理。
钩子函数是一个处理消息的程序段,通过调用相关的API函数,把它挂入系统。每当特定的消息发出,在没有到达目的窗口前,钩子程序就捕获该消息,亦即钩子函数先得到控制权。这时钩子函数即可以加工处理(改变)该消息,也可以不作处理而继续传递该消息。
总之,关于Windows钩子要知道以下几点:
钩子会使得系统变慢,因为它增加了系统对每个消息的处理量。仅应该在必要时才安装钩子,而且在不需要时应尽快移除。
SetWindowsHookEx函数可以把应用程序定义的钩子函数安装到系统中。
HHOOK SetWindowsHookEx(
Int idHook ; // 指定钩子的类型
HOOKPROC lpfn; // 钩子函数的地址。如果使用的是远程钩子,钩子函数必须放在一个DLL中。
HINSTANCE hMod; // 钩子函数所在DLL的实例句柄。如果是一个局部的钩子,该参数为NULL。
DWORD dwThreadID; // 指定要为哪个线程安装钩子。若该值为0被解释成系统范围内的。
)
IdHook参数指定了要安装的钩子的类型,可以是下列取值之一:
WH_CALLWNDPROC 当目标线程调用SendMessage函数发送消息时,钩子函数被调用。
WH_CALLWNDPROCRET 当SendMessage发送的消息返回时,钩子函数被调用。
WH_GETMESSAGE 当目标线程调用GetMessage或者PeekMessage时。
WH_KEYBOARD 当从消息队列中查询WM_KEYUP或WM_KEYDOWN消息时
WH_MOUSE 当调用从消息队列中查询鼠标事件消息时
WH_MSGFILTER 当对话框,菜单或滚动条要处理一个消息时,钩子函数被调用。该钩子是局部的,它是为哪些有自己消息处理过程的控件对象设计的。
WH_SYSMSGFILTER 和WH_MSGFILTER一样,只不过是系统范围的。
WH_JOURNALRECORD 当Windows从硬件队列中获取消息时。
WH_JOURNALPLAYBACK 当一个事件从系统的硬件输入队列中别请求时
WH_SHELL 当关于Windows外壳事件发生时,比如任务条需要重画它的按钮
WH_CBT 当基于计算机的训练(CBT)事件发生时。
WH_FOREGROUNDIDLE Windows自己使用,一般应用程序很少使用。
WH_DEBUG 用来给钩子函数除错。
Lpfn参数是钩子函数的地址。钩子安装后如果有消息发生,Windows将调用此参数所指向的函数。
如果dwThreadId参数是0,或者指定一个由其他进程创建的线程ID,lpfn参数指向的钩子函数必须位于一个DLL中。这是因为进程的地址空间是相互隔离的,发生事件的进程不能调用其他进程地址空间的钩子函数。如果钩子函数的实现代码在DLL中,在相关事件发生时,系统会把这个DLL插入到发生事件的进程的地址空间,使它能够调用钩子函数。这种需要将钩子函数写入DLL以便挂钩其他进程事件的钩子称为远程钩子。
如果dwThreadId参数指定一个由自身进程创建的线程ID,lpfn参数指向的钩子函数只要在当前进程中即可,不必非要写入DLL。这种挂钩属于自身进程事件的钩子称为局部钩子。
hMod参数是钩子函数所在DLL的实例句柄,如果钩子函数不再DLL中,应将hMod设置为NULL。
dwThreadId参数指定要与钩子函数相关联的线程ID号。如果设为0,那么钩子就是系统范围内的,即钩子函数将关联到系统内所有线程。
钩子安装后如果有相应的消息发生,Windows将调用SetWindowsHookEx函数指定的钩子函数lpfn。钩子函数的一般形式如下:
1 | LRESULT CALLBACK HookProc(int nCode, WPARAM wParam, LPARAM lParam) |
HookProc是应用程序的名称。nCode参数是Hook代码,钩子函数使用这个参数来确定任务,它的值依赖于Hook的类型。wParam和lParam参数的值依赖于Hook代码,但是它们典型的值是一些关于发送或者接收消息的信息。
因为系统中可能会有多个钩子的存在,所以要调用那个CallNextHookEx函数把消息传到链中下一个钩子函数。hHook参数是安装钩子时得到的钩子句柄(SetWindowsHookEx的返回值)。
要卸载钩子,可以调用UnhookWindowsHookEx函数。
BOOL UnhookWindowsHookEx(HHOOK hhk); // hhk 为要卸载的钩子的句柄
注意:
1 | //ke |
1 |
|
1 | // keyhooklib.def |
以对话框为基础建立工程(keyhookapp),改动的文件如下:
1 | // KeyHookAppDlg.cpp : implementation file |
一个对话框,检测当前键盘的状态。若有按键按下,则在对话框的EDIT控件中显示按下键的名字。
游戏引擎负责处理各种琐碎事务:组件游戏,确保它正确运行及关闭它。将游戏分解为事件:
下面这些事件只适用于任何游戏的部分核心事件:
初始化事件在一开始运行游戏时发生,这时游戏执行重要的初始设置任务,包括创建游戏引擎本身。启动和结束事件对应于游戏的开始和结束,这时很适合执行与特定的游戏会话相关联的初始化和清理任务。在最小化游戏或者将其发送至后台,然后在恢复时,就将发生激活和停用事件。当游戏需要绘制自身时,将发送绘制事件,类似于WINDOWS WM_PAINT 消息。最后,循环事件使游戏执行一个单独的游戏周期,它非常重要。
游戏的计时机制:
游戏在指定的时间内运行的周期越多,看起来就越平滑。事实上,大多数游戏设置都在15 - 16周期每秒的范围内,最快的速度可能达到30周期每秒,比电影还快。除了极少数的一些情况外,应该力求达到的最低速度设置为12周期每秒。
游戏引擎的类:
1 |
|
其实现文件如下:
1 |
|
其使用方法:
xxx.h文件要先声明一个全局游戏引擎指针。
1 |
|
然后xxx.cpp文件包含该xxx.h文件,在实现相应的游戏事件:
1 |
|