在多线程程序中为了保证数据一致性,一般会使用同步机制,比如,使用临界区或Mutex来加锁获取资源,解锁释放资源。用锁不当,会产生死锁(Deadlock)、活锁(Livelock)、饥饿(Starving)等问题,另外在某些对性能要求苛刻的地方,也不是最佳选择。
若把同步机制叫软件锁(Software Lock),那么原子操作可以认为是硬件锁(Hardware Lock)。而基于原子操作实现的无锁数据结构和算法,在这些需要考虑加锁/解锁效率的情况下,值得一用。当然无锁数据结构要精心设计,任何一行代码都要慎重考虑,不光是字面代码,还得考虑编译器优化,内存模型,甚至CPU架构。看一看C++11标准引入的atomic就知道有多复杂了,为了性能也是拼了。
UE中支持了无锁队列(TLockFreePointerListFIFO)和无锁堆栈(TLockFreePointerListFIFO),在TaskGraph中的任务队列就是基于此实现的,作为任务多线程调度的核心模块,性能肯定是至关重要的。更加复杂的LockFree数据结构实现起来非常麻烦,正确性也很难保证。下面主要介绍下:
- UE中的无锁队列的用法,超级简单。
- 无锁编程的关键技术点,若要自己设计一个无锁队列,要考虑哪些技术点?CAS原子操作、ABA问题、内存屏障等。
- UE中无锁队列的实现,用起来简单的背后,就没那么简单了。
- TaskGraph中无锁队列的使用。
1.UE中的无锁队列用法
无锁堆栈和无锁队列类似,仅以无锁队列为例。和最普通的队列操作类似,用起来非常简单,只不过它是线程安全的,并且对其Push/Pop都是没有加锁的。常用操作:
- Push - 添加一个Item进队列
- Pop - 弹出一个Item,队列为空则返回空值
- PopAll - 弹出所有Item到指定数组
- IsEmpty - 队列是否为空
代码示例:
1 | // 自定义对象类 |
2.无锁编程的原理
什么是无锁编程?
- 准备使用多线程编程
- 多线程需要访问共享内存
- 线程之间不用阻塞彼此(使用同步机制)
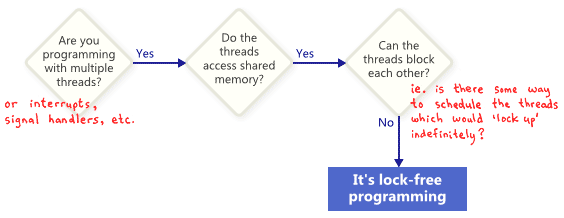
无锁编程的技术点?
同时存在多个写操作:
- 需要系统支持原子操作(RMW, Read-Modify-Write),原子操作一般都是CPU指令集级实现。
- 若你的代码里面有CAS(Compare-And-Swap)循环操作,就得考虑ABA问题。
若是多核心的CPU,需要考虑内存模型,顺序一致的?还是乱序的?这个可以通过内存屏障来解决(Memory Barrier)。
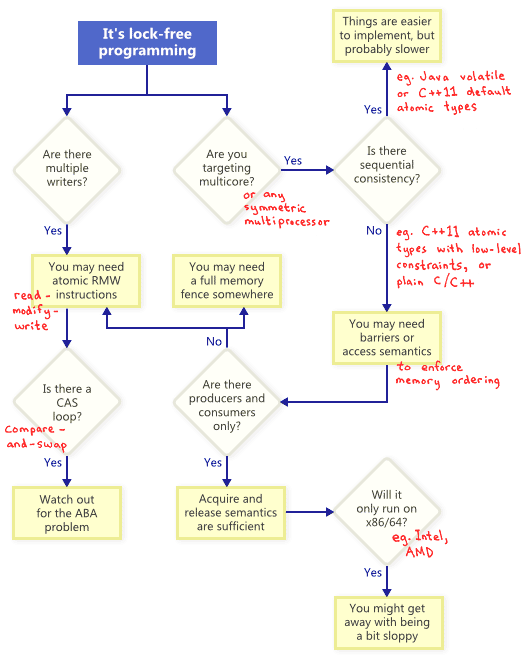
接下来重点了解下,LockFree的几大关键技术点:
- CAS原子操作
- ABA问题
- 内存屏障
2.1.CAS原子操作
CAS(Compare-And-Swap):是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。 该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
伪代码如下:
1 | int compare_and_swap(int* reg, int oldval, int newval){ |
假设要实现一个与指定内存位置的值进行AND操作,对比下非线程安全和线程安全版:
1 | // 非线程安全 |
UE中的CAS跨平台接口:
1 | // Dest - 内存位置 |
2.2.ABA问题
看到上面那个CAP的while循环,就要条件反射想到ABA问题。所谓ABA问题:
ABA问题是无锁结构实现中常见的一种问题,可基本表述为:
- 线程P1读取了一个数值AP1被挂起(时间片耗尽、中断等)
- 线程P2开始执行P2修改数值A为数值B
- 然后又修改回AP1被唤醒,比较后发现数值A没有变化,程序继续执行。
- 对于P1来说,数值A未发生过改变,但实际上A已经被变化过了,继续使用可能会出现问题。
在CAS操作中,由于比较的多是指针,这个问题将会变得更加严重。
假设要实现一个简单的无锁堆栈,不考虑ABA,如下(借CMU并行架构和编程课件一用,后面有链接):
- push操作:更新栈顶指针为新结点,通过CAP循环实现原子操作
- pop操作:弹出一个元素,更新栈顶指针,通过CAP循环实现原子操作

ABA问题的产生:
- Thread0:执行pop操作,设置完局部变量,old_top=A, new_top=B, Thread1重入
- Thread1:
- 执行pop操作
- 然后push一个D进去
- 然后又去修改A指向的对象,或者新建了一个对象,它刚好也指向A指针,然后push进去
- Thread0:Thread0这个时候重入,CAP操作发现内存中的值(A,其实是Thread1重新push进去的那个A)和old_top相同,然后更新栈顶为new_top(B)。
那么问题来了?D去哪里了?肯定不对了,这就ABA问题!
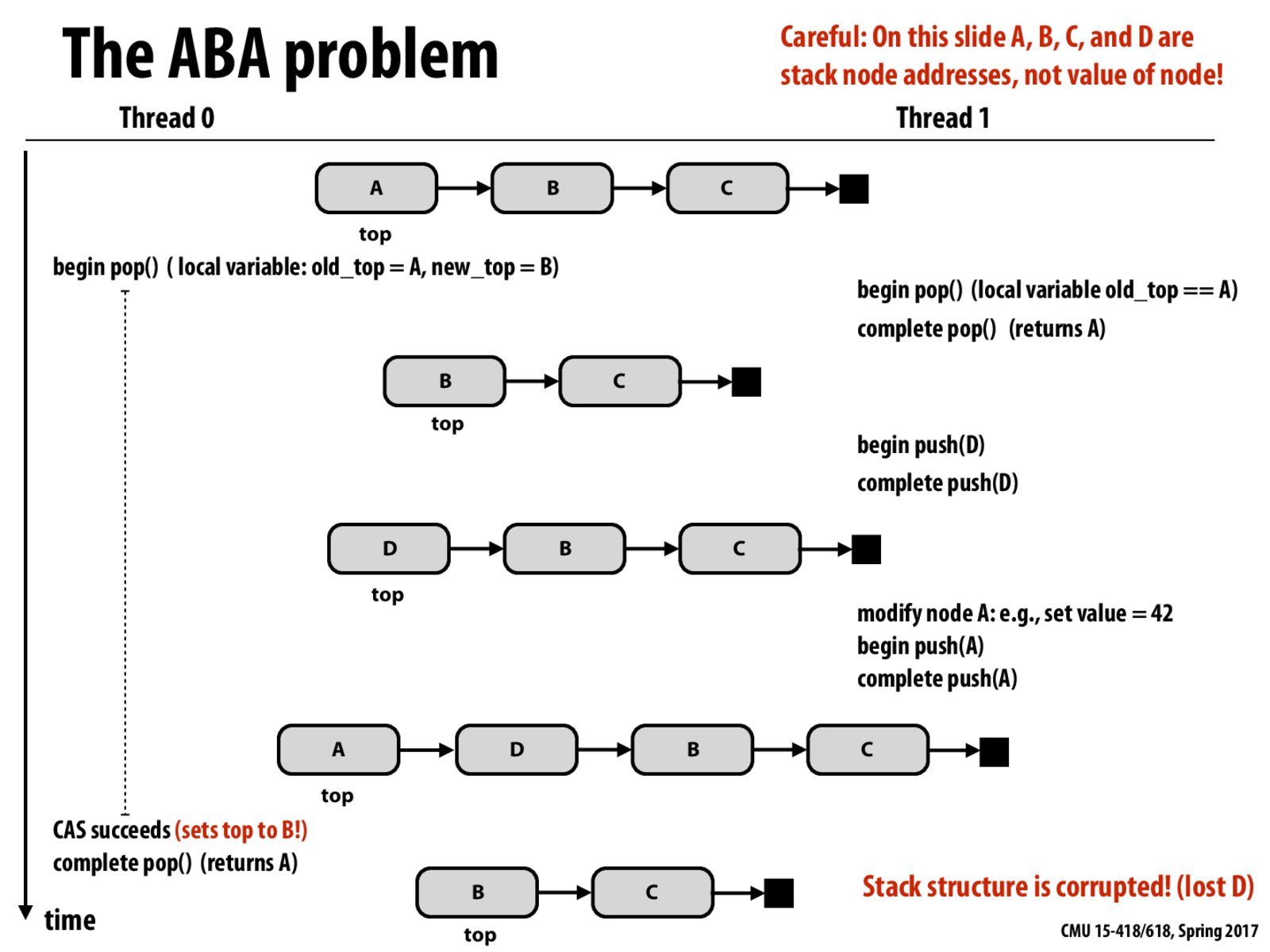
ABA问题的解决方法:
- Pop操作加上一个计数器
- 更新栈顶和Pop操作计数器,为一个原子操作
- 这样每次Pop操作时就不再是ABA,而是A1BA2了,这样只要上个Pop没完成,这个Pop就得等待了。

2.3.内存屏障
内存屏障(Memory Barrier)是用来解决内存访问乱序的问题。看一段很简单的代码(但是需要考虑多核和多线程):
1 | // 假设x、y初始化为0 |
思考下:能否出现: r1 = 1, r2 = 0的情况?
答案是:看情况!这就有点可怕了,写的多线程代码行为不确定!
2.3.1.内存模型的差异
什么情况不出现?
- 顺序一致性模型下,是不会出现 r1 = 1, r2 = 0的情况,只可能的结果如下(按顺序交替执行):
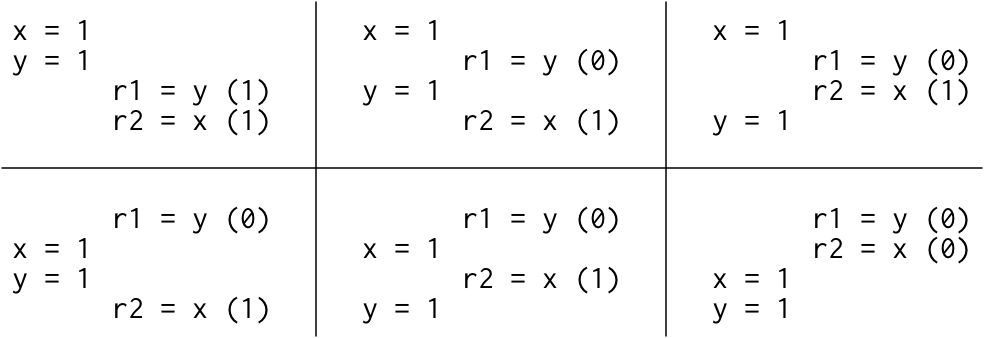
顺序一致性的一个很好的思维模型是想象所有处理器直接连接到同一个共享内存,它可以一次处理一个线程的读或写请求。 不涉及缓存,因此每次处理器需要读取或写入内存时,该请求都会转到共享内存。 一次使用一次的共享内存对所有内存访问的执行施加了顺序顺序:顺序一致性。

- x86-Total Store Order(x86-TSO)也不会出现(Intel/AMD)
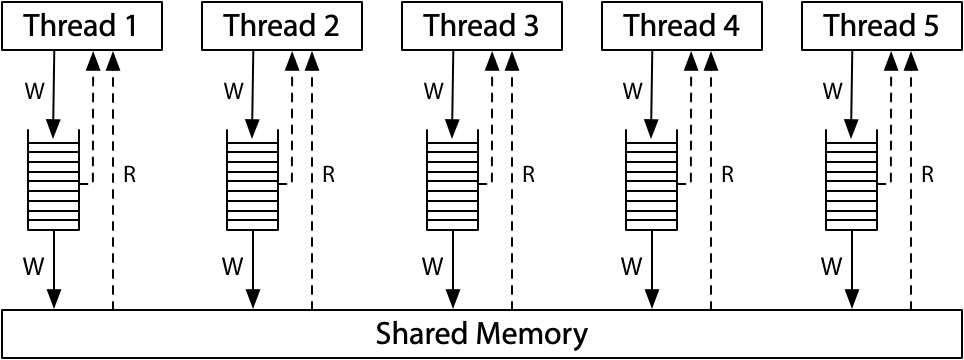
什么情况下可能会出现?
- ARM/POWER Relaxed Memory Model时,可能会出现:
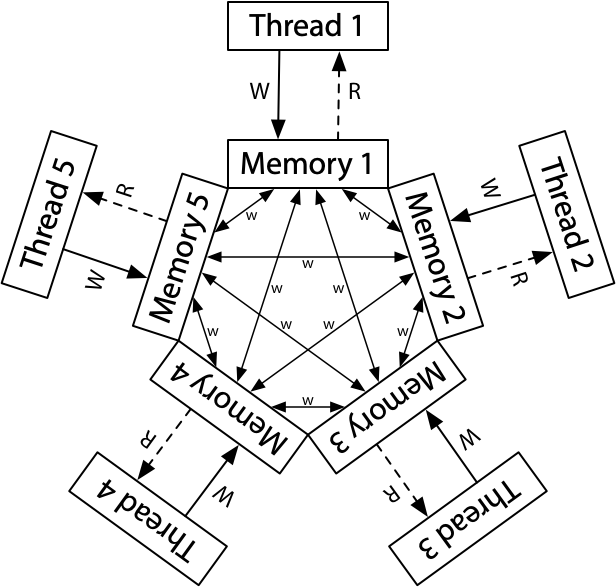
在ARM/POWER模型中,我们可以想象线程1和线程2都有各自独立的内存副本,写操作以任何顺序在内存之间传播。如果线程1的内存在发送x的更新(update)之前向线程2发送y的更新,并且如果线程2在这两次更新之间执行,它将确实看到结果r1 = 1,r2 = 0。
更进一步了解,可以参考C++11之后提出的内存模型概念,同时研究下计算机体系结构。
2.3.2.内存乱序
这种不确定主要是因为,开发者编写的代码和最终运行的程序往往会存在较大的差异,而运行结果与开发者预想一致,只是一种“假象”罢了。之所以会产生差异,原因主要来自下面三个方面:
- 编译器优化
- CPU乱序执行(out-of-order)执行
- CPU缓存(Cache)不一致性
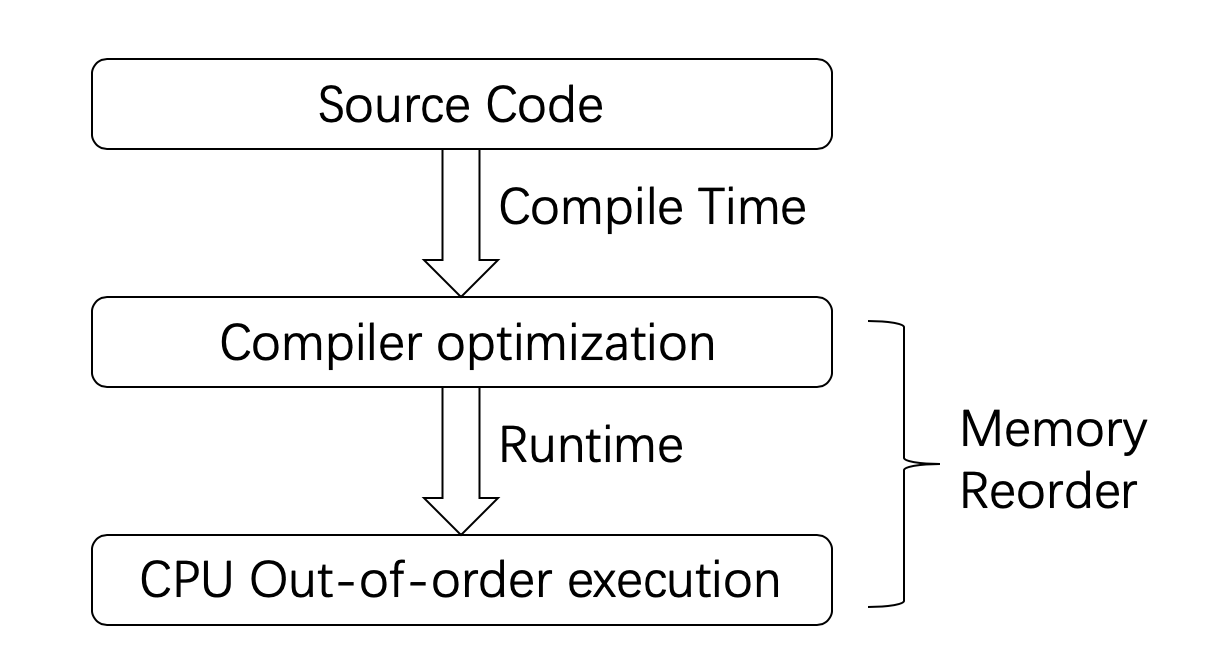
2.3.3.编译器优化导致的乱序
以gcc为例,该编译器提供了-o参数来控制非常多的优化选项。
以下面这段代码为例:
1 | int A, B; |
在编译优化后,可能会变成下面这样:
1 | int A, B; |
请注意,编译器只要保证:在单线程环境下,执行的结果和原先一样就可以了。所以,这样做是可以的。
对于编译器的乱序优化来说,开发者并非完全不能控制。编译器会提供称之为内存栅栏(Memory Barrier)的工具给开发者,让开发者告诉编译器:这部分代码编译的时候不能乱序。
gcc的内存栅栏写法如下:
1 | int A, B; |
其他编译器内存屏障的写法:1
2
3
4
5
6
7
8// C11 / C++11
atomic_signal_fence(memory_order_acq_rel);
// Microsoft Visual C++
_ReadWriteBarrier();
// GCC
__sync_synchronize();
2.3.4.CPU乱序执行
运行时产生的原因上面已经说过了,主要是因为内存模型的差异,导致的Momeory Reorder问题,常见平台的差异:

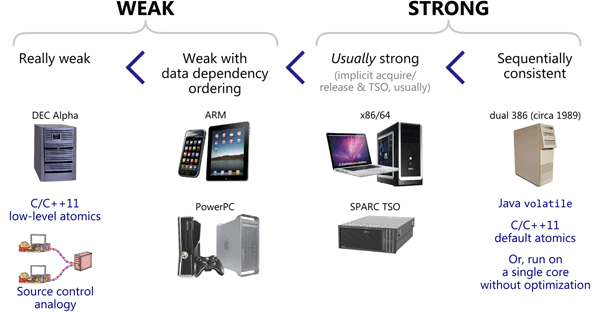
类似的,处理器也会提供指令给开发者进行避免乱序的控制。例如,x86,x86-64上的fence指令:
1 | // x86, x86-64 |
2.3.5.CPU缓存不一致
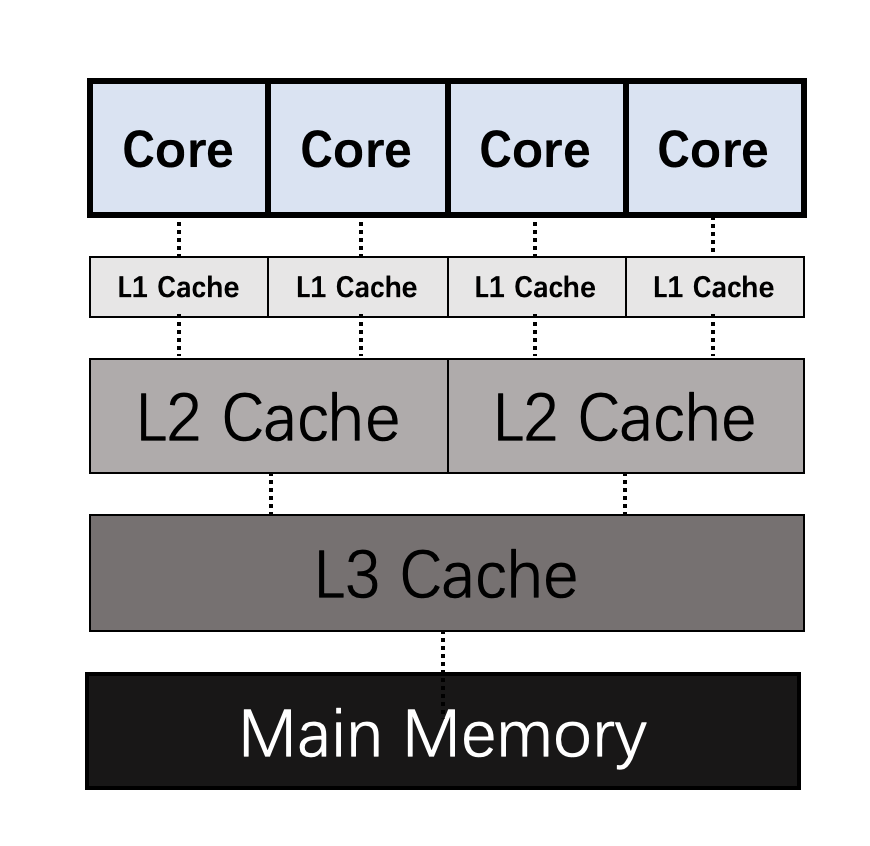
每个CPU核在运行的时候,都会优先考虑离自己最近的Cache,一旦命中就直接使用Cache中的数据。这是因为Cache相较于主存(RAM)来说要快很多。但是每个核之间的Cache,每一层之间的Cache,数据常常是不一致的。而同步这些数据是需要消耗时间的。
这就会造成一个问题,那就是:某个CPU核修改了一个数据,没有同步的让其他核知道,于是就存在了数据不一致的情况。
2.3.6.UE中的内存屏障
为了跨硬件平台,跨操作系统,可谓煞费苦心。看起来简简单单的代码,背后要考虑的事情太多太多。
1 | // 代码中直接调用 |
3.UE中无锁队列的实现
3.1.结构
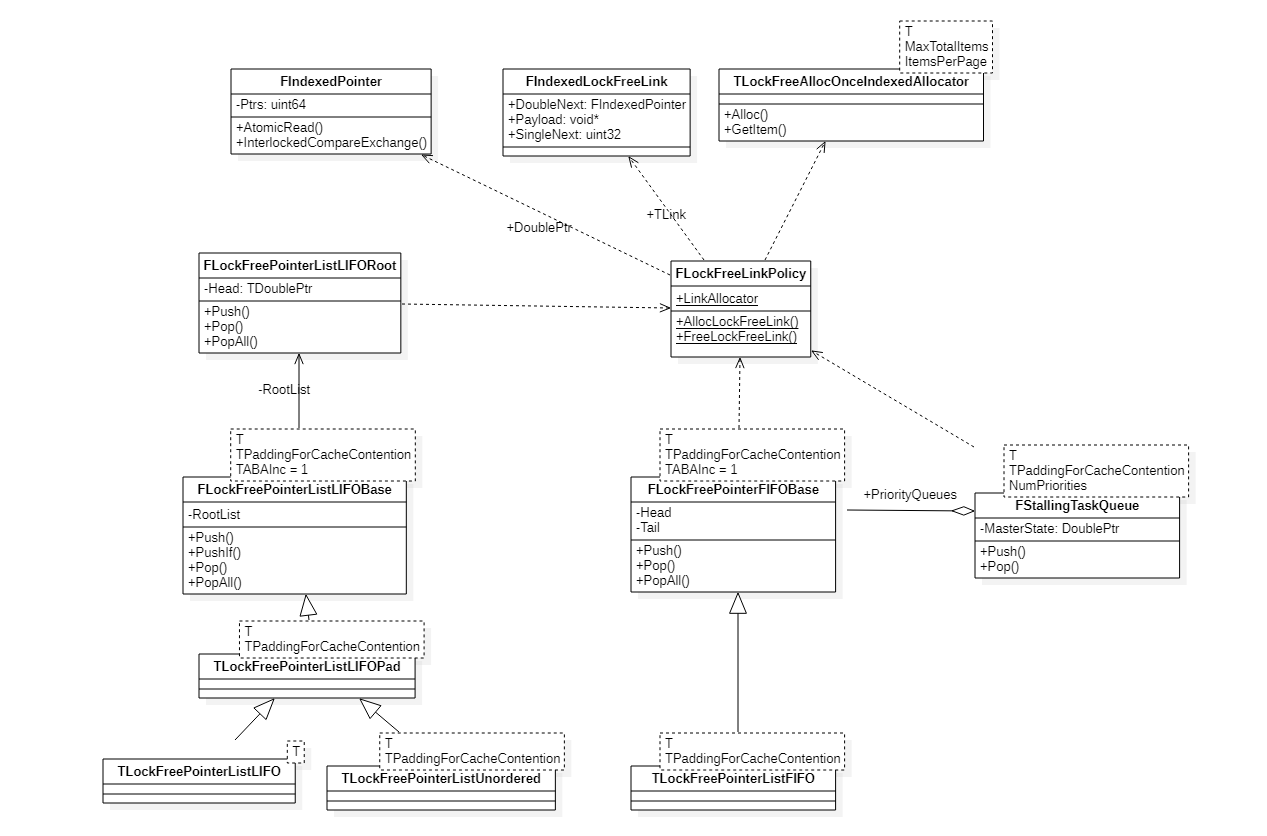
常用结构:
- TLockFreePointerListLIFO
- 不考虑内存Prefetch的无锁堆栈 - TLockFreePointerListUnordered<Type, PLATFORM_CACHE_LINE_SIZE> - 防止内存Prefetch导致的竞争的无锁堆栈。
- TLockFreePointerListFIFO<Type, PLATFORM_CACHE_LINE_SIZE> - 无锁队列(带防止内存Prefetch导致竞争的机制)
内部实现:
- FIndexedPointer - 支持原子操作的节点指针(64位,低26位表示指针索引,其他高位表示计数器或状态),最多支持2^26个节点。
- FIndexedLockFreeLink - 节点结构。
- FLockFreeLinkPolicy - 封装节点内存管理、隔离节点相关类
- FLockFreePointerListLIFORoot - 无锁堆(LIFO)核心实现
- FLockFreePointerFIFOBase - 无锁队列(FIFO)核心实现
3.2.Push/Pop的原子性
再次见到CAS Loop,及ABA问题的计数器解决方案,熟悉了原理,一看就明白了:
1 | void FLockFreePointerListLIFORoot::Push(TLinkPtr Item) |
同样的CAS循环结构,在LockFreeList.h多次出现,没有一行代码是多余的。
3.3.节点内存分配/释放的原子性
还有一个问题要解决:
创建或析构一个节点FIndexedLockFreeLink(TLink),怎么做?Malloc/Free不是线程安全的。
创建/析构链表节点的原子操作:
1 | struct FLockFreeLinkPolicy |
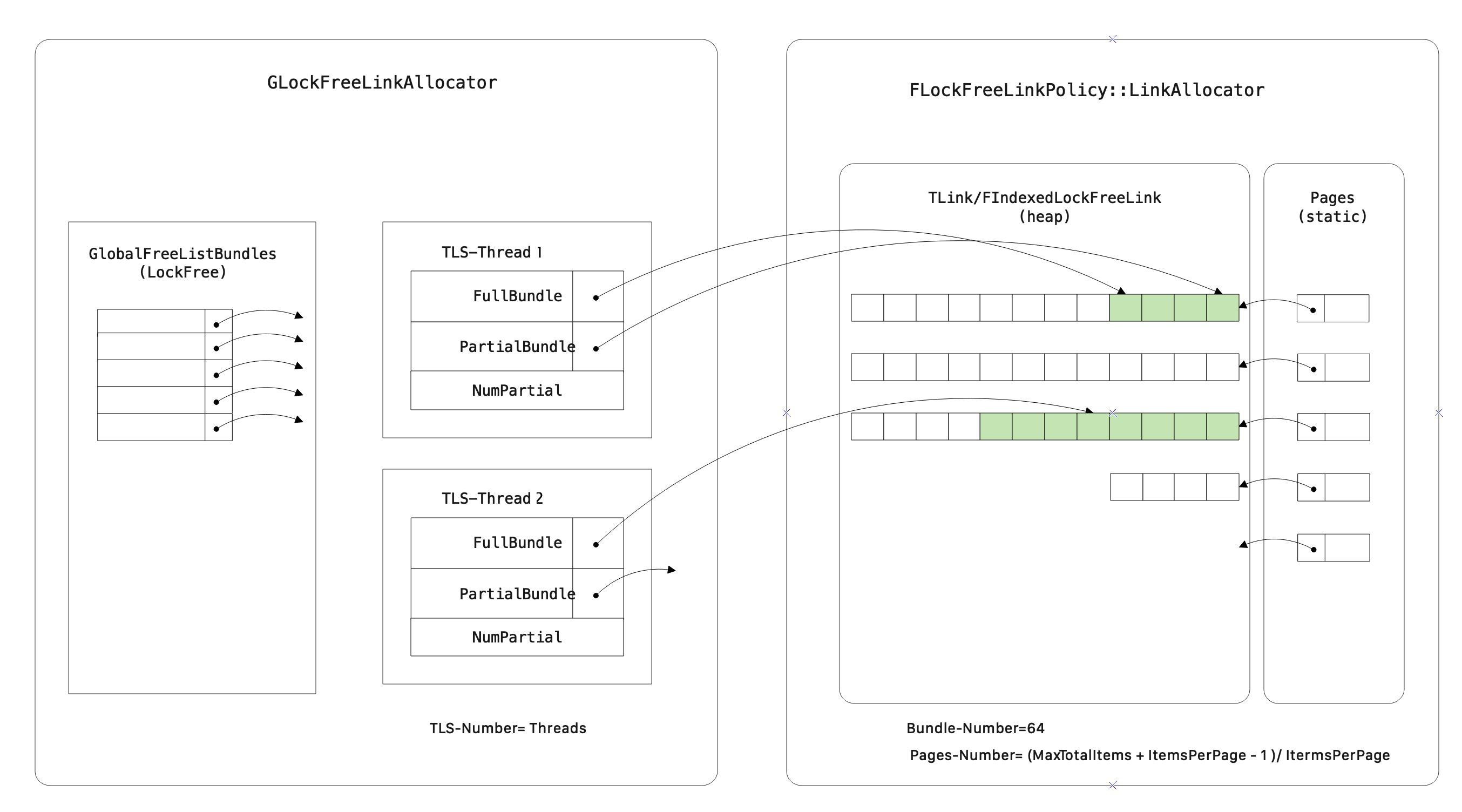
为了支持原子的内存分配和释放,LockFree的节点内存分配器包含两部分:
GLockFreeLinkAllocator,每个线程通过TLS关联一堆空闲的节点Bundle。FLockFreeLinkPolicy::LinkAllocator:LockFree节点页式分配器。- 默认在静态空间中初始化了MaxBlocks个Page指针,其中:
MaxBlocks = (2^26 + 16384 -1)/16384。 - Alloc操作在堆上按页分配内存,若页中还有空闲节点,直接返回,否则,分配一个完整页,然后返回。
- 通过Page/Subindex来索引节点
- 默认在静态空间中初始化了MaxBlocks个Page指针,其中:
内存布局如下:
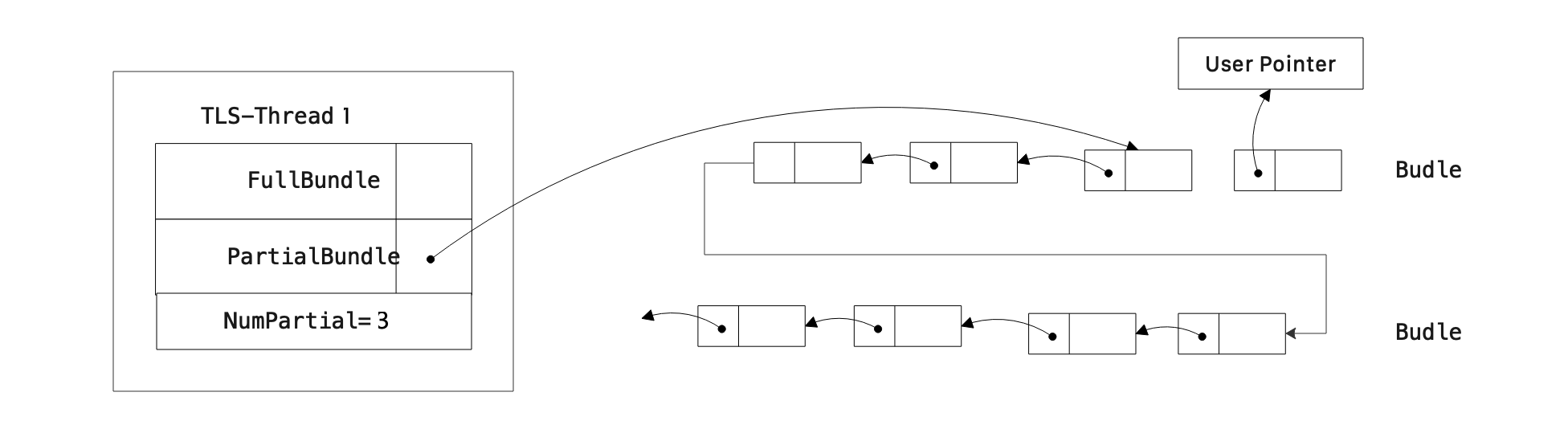
AllocLockFreeLink调用时:
- 优先从GlobalFreeListBundle中Pop一个节点对象出来, 若GlobalFreeListBundle为空,继续下一步
- 若当前线程TLS的PartialBundle指向的位置还有空节点,则返回,并移动PartialBundle指针到下一个空节点
- 若当前线程TLS的PartialBundle指向的位置没有空节点,则通过
FLockFreeLinkPolicy::LinkAllocator分配NUM_PER_BUNDLE(64)个空闲节点,返回一个空节点(该情况如下图所示,图中Bundle节点之间的箭头是
FIndexedLockFreeLink的PayLoad变量,没有对象时指向下一个空闲位置,有对象时代表对象指针)
FreeLockFreeLink调用时:
- 若当前线程TLS的中的Bundle都是空的,把要释放的对象Push进GlobalFreeListBundle
- 否则释放当前对象,并把当前线程中空位置(TLS.PartailBundle)指向当前节点位置
3.4.防止Cache Prefetch导致的竞争
在访问指定内存地址时,一般硬件/操作系统会进行Prefetch操作,预先取多个字节:
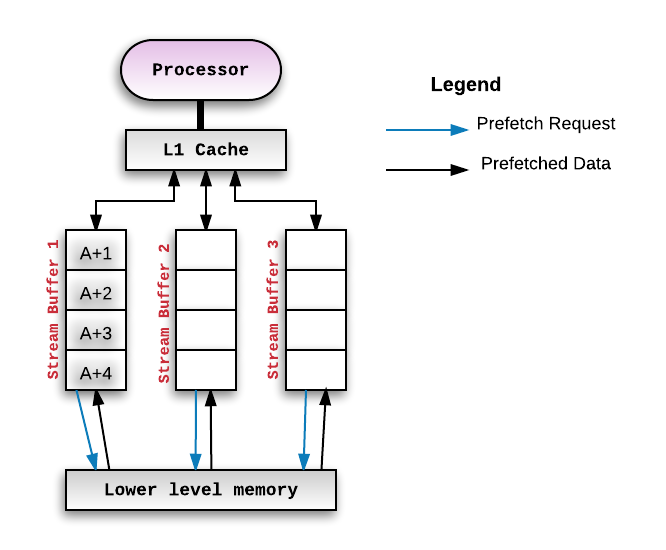
对于多线程程序来说,若我们关注的数据(比如:Head指针)被其他操作预先读入缓存,当在代码中对Head进行原子操作时,缓存数据应该需要和内存中的数据做一次同步,为了节省掉这个同步操作,应当尽量避免Head变量被Prefetch(再次体会到对性能的极致追求,和计算机体系架构的紧密性了,对性能要求没那么苛刻情况下,不限制也不影响正确性)。
UE中LockFree避免的方法是通过变量前后加上一个Prefetch大小(PLATFORM_CACHE_LINE_SIZE)的变量,以空间换取极致的性能:
1 | FPaddingForCacheContention<TPaddingForCacheContention> PadToAvoidContention1; |
4.无锁队列在TaskGraph中的应用
4.1.FStallingTaskQueue
FStallingTaskQueue:支持优先级的无锁任务队列。
- Push时需要指定任务的优先级
- Pop时优先从0-N优先级队列弹出任务,可以指定队列为空时挂起(bAllowStall=true时),直到再次有任务。
来看下TaskGraph中FNamedTaskThread中的相关实现:
1 | // 支持2个优先级的无锁队列,0-优先级,1-低优先级 |
4.2.TClosableLockFreePointerListUnorderedSingleConsumer
TClosableLockFreePointerListUnorderedSingleConsumer,好长的类名,不过通过名字大概能猜到作用:
- 可关闭的(Close标记)
- 无锁队列,带防止内存Prefetch竞争
- 支持单消费者线程
- 继承自FLockFreePointerListLIFOBase
在FGraphEvent中用来表示任务的后续任务列表:
1 |
|
5.小结
要想写好多线程代码,难吗?挺难的,有篇300多页的文章回答这个问题(Is Parallel Programming Hard, And, If So, What Can You Do About It?)。从计算机体系结构说起,到内存模型,同步机制,再到并发数据结构的设计,实在是没法再展开了(相关资源,见参考资料中的链接)。
用UE多线程/Async/TaskGraph做并发编程,难吗?代码很简洁,简洁的背后是复杂的设计和考量,好在UnrealEngine已帮你封装好了。
切记:写多线程代码时,一定要明确知道你的每一行代码在那个线程中执行的!
6.参考资料
An Introduction to Lock-Free Programming :
https://preshing.com/20120612/an-introduction-to-lock-free-programming/
Parallel Computer Architecture and Programming
Is Parallel Programming Hard, And, If So, What Can You Do About It?:
https://mirrors.edge.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.2011.01.02a.pdf
Hardware Memory Models:
https://research.swtch.com/hwmm.pdf
https://research.swtch.com/plmm.pdfC++内存模型:
UE Source Code:
Engine/Source/Runtime/Core/Public/Containers/LockFreeList.h
