整天和计算机打交道的人,如果一直用手工去做一些重复的事情,那么你就是在犯罪。如果说时间就是生命,那么重复就是在挥霍自己的生命,同时也在浪费别人的生命,因为当你手工低效率做事的时候,别人也在等着你。
程序员的世界,最讨厌的就是重复,重复的事情应该交给机器来帮你完成,而并非同样的事情手动敲了一遍又一遍。人脑最擅长的是通过思考总结、分析、抽象出模式,而机器最擅长的就是重复。机器执行重复的事情,准确性和效率要完胜手工。机器做重复的事情,当然是通过编程来实现,包括:脚本,宏,使用自己或别人开发的各种工具等。要做一个比较懒的程序员,学会使用工具和脚本,现有的工具不能满足你的要求,那么就需要自己挽起袖子自己造一个了。把重复的事情交给机器来做,你要做的就是分析抽象出重复的模式,然后将它转化成工具。
事不过三,事不过三,事不过三!再重要的事情最多也只能说三遍,再说估计打我的心都有了!
工作篇
搭建弹窗服务
一个流氓服务,运营就喜欢这样的东西,不得不接手搭建。花掉两天时间折腾,Mongo集群搭起来后,导数据和数据清理花了不少时间。近100G的数据文件,清理完差不多还剩50G左右。话说,代码量不大,看代码加上搭建测试环境调试花了半天基本就知道是怎么回事了,数据却让人折腾了好一番。之前也没搞过MongodDB集群的数据备份,直接把人家一个机器上的整个库目录复制过来了,问题层出不穷,一遍查文档一边折腾这些数据,最终还是跑起来了。处理客户端请求的服务效率还行,扛得住,后台管理员页面的处理那简直是玩死人的节奏啊,设计的明显有缺陷,有时一个操作可能涉及几百万用户时卡个2个小时才能搞定。后果可想而知,运营的同学们都抓狂了,我也无能无力了,改代码是来不及了。
游戏区重组脚本
干完运营的活,又得折腾策划的事情。合区之前是有的,非得搞一个变态的国家打乱重组,需要的区的数量还不定。很早之前,好像干过这么一次,两个区进行国际重组,也是仅有的一次,是运维同学自己写的SQL语句。如今,区的数量不定,如果还是手动写的话,SQL脚本随着区的数量增多会越来越复杂。
重复就是犯罪,那么直接用Python脚本写吧。重组的规则由策划制定,使用XML做配置,形如:
1 | <newzone id="200" newdb="new1"> |
执行过程有两种做法:
1>. 创建好N个新区DB,然后从旧DB中拉数据。
2>. 把所有旧DB进行合并,复制成N份,然后每一个COPY删掉不相干的数据。
第一种做法效率要高些,要安全些,不会产生多余的数据,上线后缺什么东西从旧DB里面拉过来就行了。那么问题来了,下周就要这么干了,这个过程从来没有测试过,万一出问题就玩大了。而之前合区的操作则是跑了好几年了,相对要稳定些,最后还是选择了后一种方式。暂时只是3个进行重组,合并后的DB有20G左右,以后如果要重组的个数较多,合区也需要点时间了。
学习篇
MongodDB集群
刚接触MongoDB,就要用到它的集群,只能硬着头皮短时间去看文档和尝试自行搭建。迁移历史数据更是让人恼火,近100G的数据文件,导入、清理垃圾数据执行的速度蜗牛一样的慢。趁着这个时间,把这几天关于Mongod集群相关的内容整理一下。大概介绍一下MongoDB集群的几种方式:Master-Slave、Relica Set、Sharding,并做简单的演示。完整介绍参考前一篇文章:高可用的MongoDB集群
写论文的利器XeLaTex
论文里面要包含各种公式、图表、数据、代码,WORD难倒不能胜任吗?国内多数大学的论文模板都是WORD的,为啥不用WORD呢?写过论文的同学都知道,论文内容先不论,那破格式要求能把你折腾个半死,有多少人的论文被打回来都是因为格式不满足要求?
TeX系统从它诞生的第一天,就是要让写作的人只关心内容,排版全部交给Tex系统搞定,有特殊的排版需求,只需要随便配置下即可。特别是对于数学公式的排版,那是相当的漂亮。Tex是什么?你可以Google一下,是计算机大神Donald E. Knuth(高德纳)发明的排版系统,在写作《计算机编程艺术》那几本神书的时候,发现没有合适的排版工具,大神就动手自己写了一套排版系统(忽然脑子里面飘过Linus大神的分布式版本控制工具git,也是在为linux内核找一个合适的开源版本管理工具的时候,发现没有合适的,于是乎自己整出来一个,有点异曲同工之处)。后来美国计算机学家莱斯利·兰伯特(Leslie Lamport)在20世纪80年代初期在TeX系统的基础上,做了一个宏包,就是有名的LaTex。这位是干啥的?分布式一致性算法:Paxos的作者,他对分布式系统的发展做出了许多牛逼的理论支持。之前的TeX和LaTex对于中文都不支持,需要挂载额外的包才可以正常的显示中文(如:CJK包),XeTex在原来TeX的基础上增加了对Unicode的支持,XeLaTex就是LaTex + XeTex,本身就支持中文和多国字体,不要挂载其它宏包了。关于TeX、LaTex还有其它类似的Tex系统有着说不完的故事,有兴趣的可以去Google一下。
接触LaTeX是在本科的时候,没有像样的写过东西,只是觉得好玩。如今,刚好派上用场,专心内容,形式的东西交给XeLaTeX搞定。讽刺的是,国内论文竟然只收WORD的,无所谓了,大不了写完后再被WORD虐一遍,公式直接截图,总比使用什么MathType的要好得多。
先秀一下LaTeX的Web显示(下面就是电磁场理论的核心:Maxwell’s Equations):
LaTex脚本:
1 | \begin{align} |
显示结果:
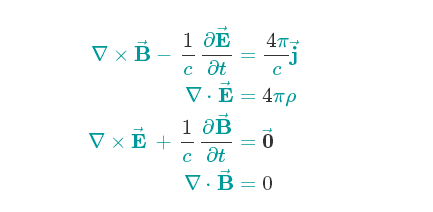
由衷的说声:真TM漂亮,公式漂亮,显示的也是相当漂亮。
总结篇
忙碌却毫无意义。这一周基本上都是在忙工作上面的事情,办公室里面来回跑个不停,话说这座位安排的真TM的太不合理了,时间全浪费在跑路和沟通上面了。
懒应该是程序员的优良品德。这里的懒并不是指你什么事情都不做偷懒,而是说能让机器做的事情坚决不自己上手,节约的时间用来学习或者干其他事情。哎,在我们这里,无论你效率有多高,手里总有忙不完的事情。你牛,那就给你更多任务,你牛,那就给你更少时间。额,结果离职的离职,没离职的天天疲于奔命。偶尔,真的偷偷懒我看也是要得的,这不就在偷懒写什么每周回顾。哈哈。
